2022.04.06
仮想脳「NeuroAI」に続け!近大生がAIを構築して2022年のヒット曲を予測してみた

- Kindai Picks編集部
2464 View

ヒット曲を予測する。そんなことができればカッコイイと思いませんか?歌のうまさ、ドラマの主題歌になること、所属事務所の強さ、SNSでバズるなど……今の時代、ヒットの要因は多様化しています。ですが、ヒットする楽曲には共通する特徴点があるかもしれません。今回は過去にヒットした楽曲約10000曲を分析して、一定の仮定のもと、AIを構築。ヒット曲の予測に挑戦してみました!
この記事をシェア



 リンクをコピーしました
リンクをコピーしました

こんにちは、理工学部情報学科4年生の清水大良です。データ分析系のエンジニアを目指して日々勉強に励んでいます!! ところで皆さんは「ヒット曲を予測する」、そんなことができればカッコイイと思いませんか?
もしヒット曲が予測できるならば、CDショップならヒットする確率の高いアーティストのCDを多く取り寄せて、売り上げアップに繋がるかもしれません! 夢見るアーティストなら、効率よくヒット曲を制作するヒントになるかもしれません!

歌のうまさ、ドラマの主題歌になること、所属事務所の強さ、SNSでバズるなど、今の時代は楽曲のヒットの要因が多様化しています。
ですが、ヒットする楽曲には、楽曲自体に共通する特徴があるのではないでしょうか?

例えば、あいみょんの「マリーゴールド」のAメロとサビ、Official髭男dismの「Pretender」サビには、カノンコードと呼ばれるコード進行が使われています。音階の変化が滑らかで綺麗なため、耳馴染みがよく、多くのヒット曲に使われているコードだったりするんです。
今回は、過去にヒットした楽曲とヒットしなかった曲、合わせて1万曲のデータを用意して、「ヒット曲には共通する特徴点がある」という仮定のもと、AIを構築してヒット曲の予測に挑戦したいと思います!!
それではさっそくAIを構築していき……
と、その前に!!! 気になる記事を見つけました!!!
脳科学とAIで音楽トレンドを可視化、ヒットソング予測に成功
なんと、国内大手のIT会社である株式会社NTTデータ、株式会社NTTデータ経営研究所、株式会社阪神コンテンツリンクの3社が共同研究をして、ヒット曲の予測に成功していました!!!
記事によると、特定の映像や音声を感知したときに、人間の脳がどんな活動をするかを推定する「NeuroAI(ニューロエーアイ)」を開発して、それを用いてヒット曲予測に成功したとのことです!!!
……。
……。
……。
ほ、ほう……。

に、人間の脳がどんな活動をするか推定する にゅ、にゅ、にゅーろ えーあい……。脳科学なんてさっぱりわからない! 開発の規模もスキルも、大学生1人とは桁違い(笑)
それにしても、どうやって予測に成功したのか、そしてNeuroAIの仕組みが気になって仕方ありません!!
そこで!! ダメもとで「NeuroAI」の開発に携わった方とお話させていただけないかお願いしてみたところ、なんとご快諾いただきました!
研究を行った株式会社NTTデータ経営研究所の茨木拓也さんに、どのようにヒット曲の予測を行ったか、分析する際の注意点など、お話を聞いてみました。
脳の仕組みをAIで再現し、ヒット曲制作を支援するすごい人に聞いてみた

お話をうかがった、 株式会社NTTデータ経営研究所 情報未来イノベーション本部 ニューロイノベーションユニット/ アソシエイトパートナーの茨木拓也さん。

本日はよろしくお願いします。

よろしくお願いします。
脳の動きをAIで再現する!? NeuroAIの仕組みについて
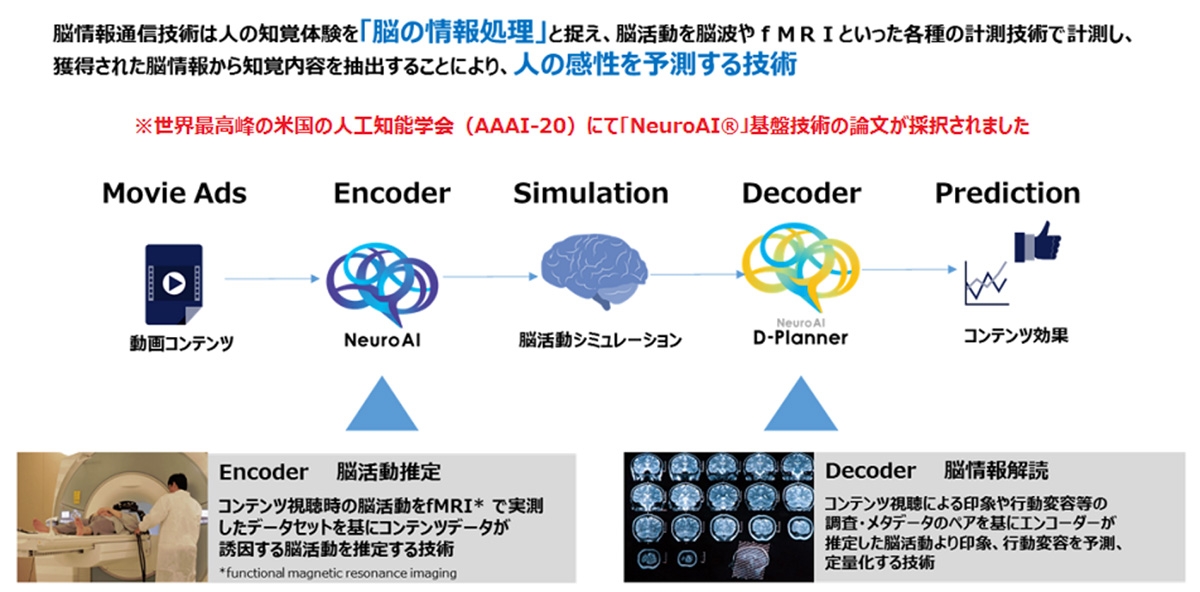
脳情報通信技術から生まれた「NeuroAI」。脳活動をAIで予測することで、コンテンツのヒットや最適化に繋げることを目的としている。
茨木さんも開発に携わった「NeuroAI」を使って、ヒット曲の予測に成功されたとうかがいました。そもそも「NeuroAI」とはどういったものなのですか?
「NeuroAI」というのは「ニューロテクノロジー」と呼ばれる技術によってつくられたAIの一つです。
ニューロテクノロジー??
人間の脳の働きを科学的に解明しようとする「脳科学」と、それを技術的にビジネスの分野などに展開できるよう、応用した分野が「ニューロテクノロジー」です。ニューロテクノロジーは3つの技術で成り立っています。一つは、MRIなどの脳計測装置を使って、情報処理を行っている脳の中の情報を読み取る技術。あとは脳に情報を書き込む技術と、脳の情報処理の様子をコンピュータで再現する仮想化技術。これらを総称してニューロテクノロジーと呼んでいます。
ほうほう。
ちなみに、脳に情報を書き込む技術に関しては、今回のヒット曲予想には使用していないんですが、記憶に関する脳活動をうながす電気刺激を、夜に人が寝ているあいだに外部から与えてやると、記憶力が上がるといったことがわかっていまして。
記憶力が上がる!? TOEICの点数が伸び悩んでる僕としては、是非とも使いたいです……(笑)
そして私たちが開発した「NeuroAI」についてですが、ニューロテクノロジーの中でも脳の情報の読み取り技術と、仮想化技術を応用した取り組みになります。
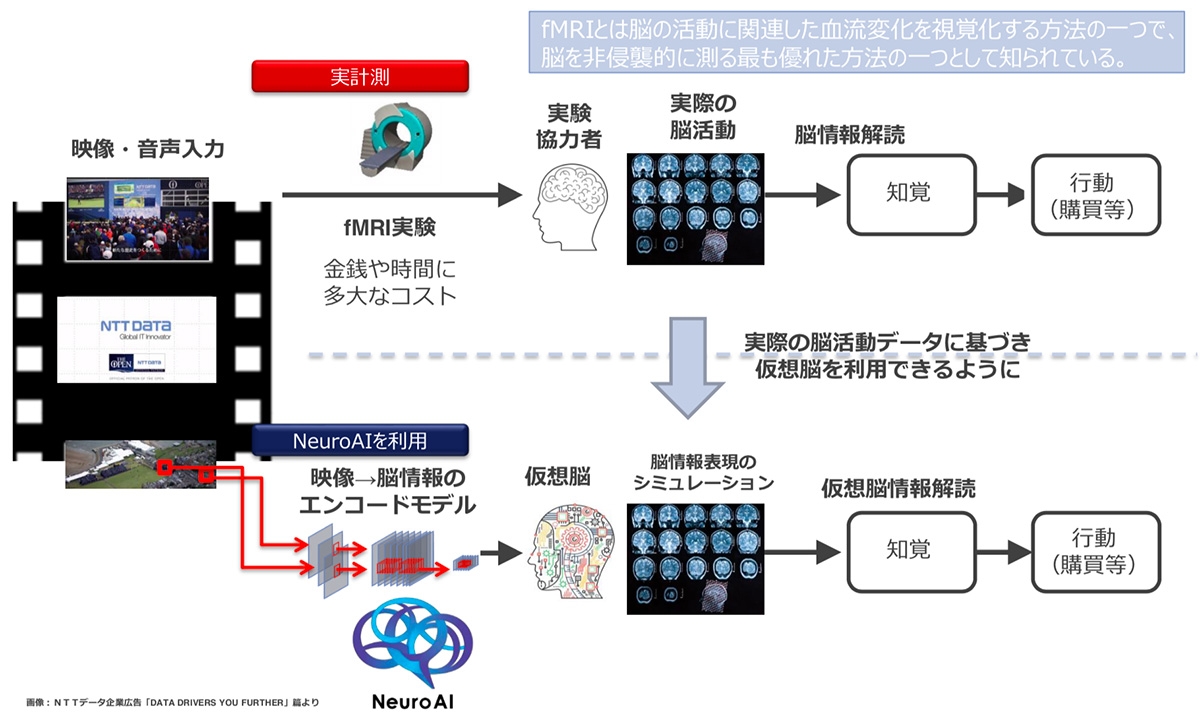
「NeuroAI」を利用した脳の仮想化についてのイメージ図。実際に人に教職してもらう計測は金銭的・時間的なコストがかかるが、「NeuroAI」の仮想脳を用いることでそれらを解消できるメリットがある。
脳の活動を観測してシミュレーションを立てた内容をAIに学習させ、人の脳と同じような動きを実現させたのが「NeuroAI」ということですね。脳の動きをコンピューターで再現することで、どうしてヒット曲の予測ができるんですか?
fMRIを使って人の脳を測ると、脳活動によって起こる血流の変化を知ることができます。つまり、あるものを見たり聴いたりしたときに、脳がどういった活動パターンで情報を表現しているか解読することができるということ。脳活動というのは、私たちの体験が暗号化されたいわゆる「脳の言葉」です。
何かを見たり聞いたりしたときの脳活動……。
つまり脳活動パターンのデータをたくさん用意して、それに対して機械学習を用いることで、実際の脳を測らなくても脳活動を推定できるようになったということですね。
すごい! 具体的にデータ集めはどんなことをされたんでしょうか?
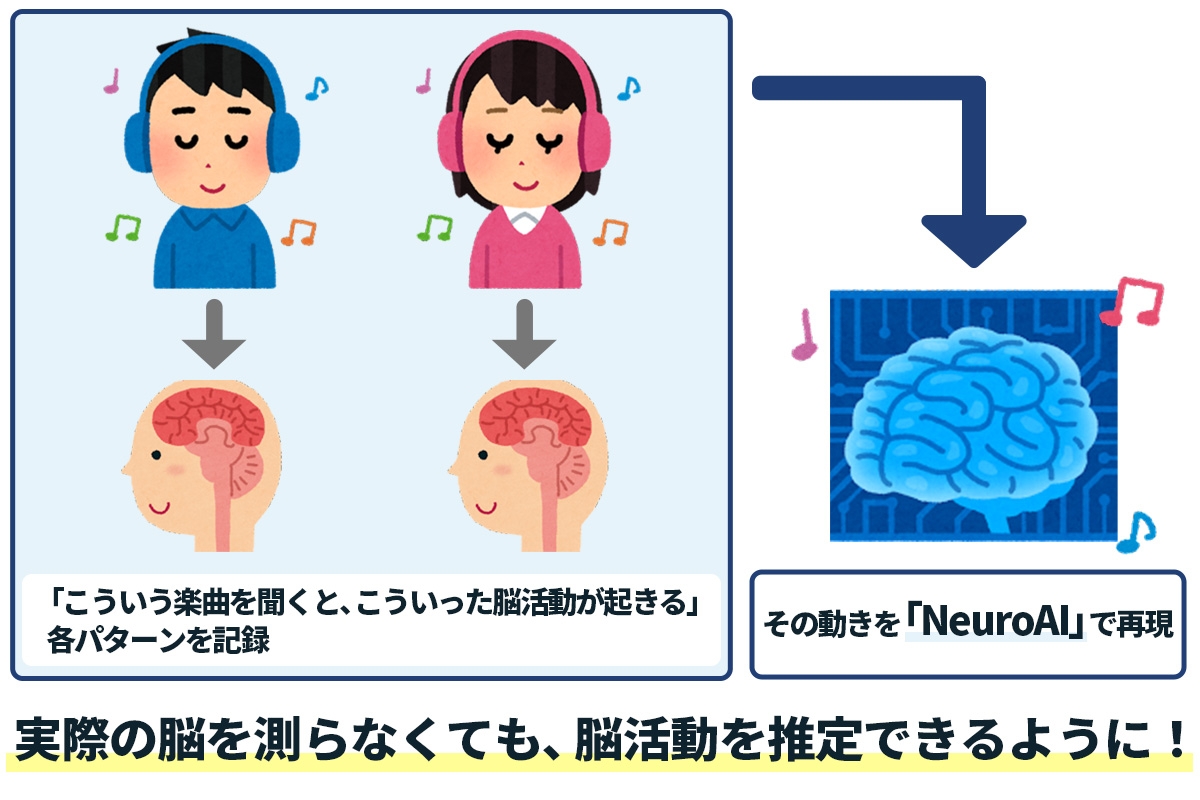
およそ100名の被験者さんに、fMRIと呼ばれる装置のなかに入っていただいて、様々な動画・音声を視聴中の脳活動を撮影しました。そこから何がわかるかというと、「こういう楽曲を聞くと、こういった脳活動が起きる」といった、その人の脳活動のパターンを取得することができます。そして様々な事象に対する脳活動データを書き溜めることによって、楽曲視聴時に発生する脳活動を予測できるようになりました。つまり、ある楽曲を聴いたときの脳内のシミュレーションができるようになったということです。
それにしても、脳活動のシミュレーションを実現するには100人ほどの脳活動のデータ量では少なすぎる気がします。万人の脳活動を再現するのであれば、データ量は多ければ多いほどいいんじゃないでしょうか?
もちろん一人一人の脳活動は異なりますがみんな同じ人間だし、地球上でみな生きているのである程度の共通性があるんです。海は海だし空は空、というように。それでいうと、100人くらいの脳の情報パターンを持っておけば、一般的な人類の脳情報表現というのは、十分取得できると考えています。

そうなんですか……!
ただ、価値観は人によって変わってきます。海を見たときに、「海を見た」と思うところまでは一緒でも、それが好きだとか嫌いだとかで個性が出てくるので、その辺は別のデータと組み合わせて、分析を行う必要があります。
つまり、価値観は人によって差異があるけれど、あるものを知覚したときの脳活動自体はほとんど同じなんですね。
空を見たらみんなが「空だな」と思うという点ではその通りです。脳を構成する神経細胞……いわゆる「ニューロン」は脳内に140億個ほどあるのですが、今のところ「NeuroAI」では1000個程度に圧縮した情報しか表現できません。しかし、それでも音楽に対する人間の脳情報を、人工の脳としてコンピュータ上で再現することができます。脳の情報には主観や言葉では表現できないみなさんの「感性」というか、体験が表現されているはずで、既存の誰かが決めた音楽ジャンルなどのラベルに捉われず、「脳の活動」として音楽体験を定量化することが可能になりました。
脳活動に基づいた音楽の分類……どんな結果が出たのかすごく興味があります。
「香水」と「天城越え」は似てる!? NeuroAIによる楽曲分析
どういう音楽を聞いたときに脳の血流がどう変化するのか、実際に分析を行ってみたんですね。結果、瑛人さんの「香水」は、石川さゆりさんの「天城越え」に似ていたり、King gnuさんの「白日」はAvicilさんの「Waiting for love」に似ていたりすることがわかりました。
「香水」と、演歌の「天城越え」が似ているんですか……! 歌の内容や世界観もずいぶん違うと思うんですが、意外な結果が出ましたね!
そうなんです。そこが「人間の主観に頼らない、脳の活動に基づいた音楽の分類」の面白さですね。そして、Billboard JAPANさんから2016年の12/5週から2020年の7/20週まで、毎週のチャートデータを提供していただいて、脳活動データと組み合わせて分析を行いました。
いよいよヒット曲予測についてですね!!
脳活動の情報というのは、その楽曲の特徴を表すデータの一つで、加えて楽曲の周波数・拍子・コード進行なども用いて、どんな楽曲が流行るのかという予測式が表せるようになります。簡単に言えば、ある特定の週のチャートデータはy=f(x)の形の式で表せるということです。
ある楽曲を聴いたときの脳情報、楽曲の周波数・拍子・コード進行などの情報(説明変数)でヒットする度合い(目的変数)を数値的に予測したということですね!!
その次に、楽曲の流行には周期があるのではないかと考えました。つまり「ある脳活動を発生させる曲調の楽曲が、ある年には流行ったけど、翌年は別の特徴を持つ楽曲が流行りそうだ」といったことがわかれば、楽曲のトレンドを予測できるということです。
流行りの周期も予測対象なんですね。確かに、数年前の曲を聞くと「古いなあ」と感じるけど、20年とか、もっと前の楽曲だと逆に新しさを感じることがありますね。
そうですね。週ごとの「ヒット予測式」がどのように変化していくか分析し、上記の考えに基づいて未来にどんな曲が流行りそうかを算出し、結果としてヒット曲の予測を行いました。
ちなみに、歌詞の影響はありますか? 例えば、Adoさんの「うっせぇわ」って、世の中に対する不満を歌ったことで、若い世代を中心にヒットしたと思っているんですけど。
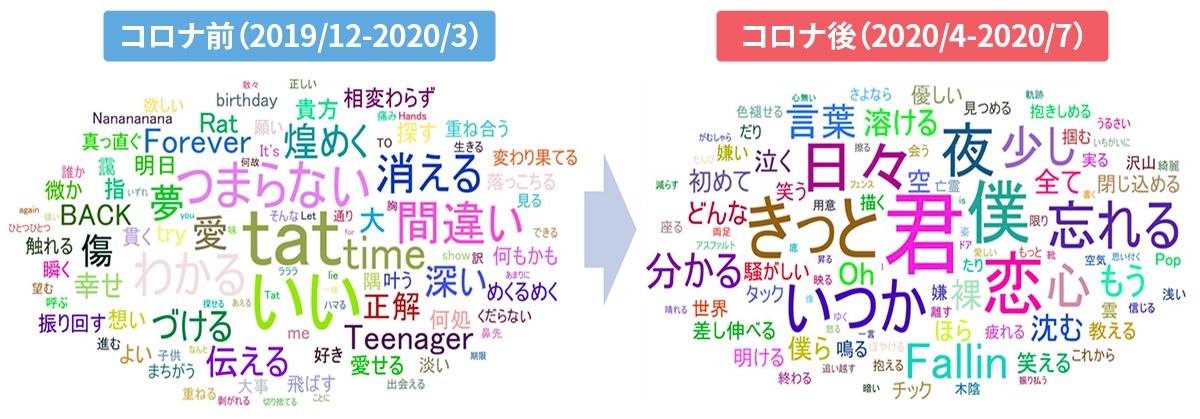
分析した楽曲全てではないんですが、歌詞が取得できる楽曲については、分析対象に入れています。例えばコロナ禍の前と後では、けっこう歌詞に出てくる単語が変わってきていて。「夜」のシチュエーションを歌った歌詞や「忘れる」「いつか」「きっと」などの、諦観的な言葉が増えています。また、一般的な愛そのものを歌ったものよりも、「君と僕」など、クローズドな世界で歌詞が展開されている傾向にありますね。
すごく聞き覚えがある単語ばかりです(笑)。内向的な歌が増えているんですね。
世相と音楽って関係性があって、困難な社会情勢だと暗い曲が売れる傾向があるんですよね。セオリーとしては、テンポが遅くてスタンダードではないキーの曲が売れる傾向があります。
なるほど。それを知っていれば、時代感に応じた、つまりヒットしやすい曲をつくりやすいですね。ちなみに、ヒット曲を予測した分析結果はどういったところに活用されているのですか?
アーティストの新人発掘のような機会で活用しようとレコード会社さん等とプロジェクトを進めています。現状では採用者の勘と経験で行われているところを、歌唱データの分析結果に基づくことで、より公平かつ効率よくアーティストを獲得することが期待できます。あと、アーティストがアルバムをつくるときに、表題曲選びで活用するとか。今後はユーザー向けに、脳活動に基づいた、よりバズる歌い方のアドバイスなんかの技術開発にもチャレンジしていきたいと思っていますね。
ここからエンジニアのマニアックな会話になるので、何を言っているのかわからない人もいると思うのですが、僕はすごく楽しかったのでもう少々お付き合いください。
じつは……私もヒット曲予測をやってみようと思っています。これまでの実体験として、モデルを構築する前に、必要なデータの収集、加工だけでギブアップしたくなるくらい時間と労力を要しました。ちなみにデータを加工する上での正規化と標準化の使い分けってありますか?
ヒットする曲ってのはほんの一握りで、とてもロングテールな分布になるので、対数変換して正規分布に近づけていく必要がありますね。
今回ヒットするかしないかで分類予測を行うのに、SVM、ロジスティック回帰、ランダムフォレストなどたくさんあると思うんですけど、アルゴリズムの選び方って茨木さんはどうしてますか?
まずは目的が何かでアルゴリズムは変わってきますよね。我々が今回ヒット曲を予想したのは、チャートデータが手元にあって、トレンド予測をするのが目的だったんですよ。チャートのポイントが連続変数なので、分類モデルじゃないなって思って。そして、特徴量が何次元あるのかが重要なんですが、清水くんは何をもとに分析しようと思ってるんですか?
音楽配信アプリの「Spotify」から得られる13種類の特微量を使おうと思っています。
Spotifyを用いた場合だといろいろ選択肢はあると思うけど、脳活動だと数百〜数千次元でワイドデータと、楽曲データに対しての次元数が多くなってくるので、スパースモデリングなんかはいいよねという話にもなってくる。トレンドの予測というのは、つまり時系列の予測じゃないですか。結果として、LSTMを使って時系列予測を行うことになりました。
何を目的とするかで、分析のアプローチも変わっていくということですね。僕はトレンドがあるとしても、ヒットする楽曲には共通する普遍的な要素があるのではないかと思い、その仮定のもと、ヒットした楽曲としない楽曲で分類を行おうと考えています。この方法である程度の分類精度が出れば、仮説が正しかったと言っていいのでしょうか?
気をつけないといけないのは、トレーニングデータの精度なのかテストデータの精度なのか。ヒットした曲としない曲を同数で学習させたなら、50パーセントを超えれば意味のある分類はできているはず。なので、テストデータで50パーセントを超えられるかが観点かなと思います。先行研究もいろいろあるので、そういうのも参考にしたらいいと思います。
わかりました! とても勉強になりました!! ありがとうございました!
ありがとうございました。
いよいよ自分でやってみよう! ヒット曲予測モデルの構築

茨木さんからうかがったお話も参考に、予測モデルを構築していきましょう。実行環境はGoogle Colaboratoryを使用して開発していきます。
ヒット曲を予測できるAIを構築するには、AIに過去にヒットした曲としなかった曲を学習させる必要があります。そこでまず初めに、AIに学習させるのに用いる楽曲データを準備していきます。
今回の分析では、ヒットする曲を「BillboardJAPAN HOT 100 に選ばれたことがある曲」と定義して、2010年1月から2022年2月までの各月初週の週間ランクに選ばれた楽曲情報(アーティスト名、楽曲名)をBillboardサイトから抽出していきます。
効率よくモノを動かすための前段階がものすごく大変なのが、エンジニアリングの世界。
茨木さんの話にもありましたが、こちらが望む分析をしてくれるようにAIや機械学習モデルに読み込ませる「トレーニングデータ」、構築したAIが正しく動作してくれるか最終確認用の「テストデータ」など、用途や目的に合わせた情報の入力が必要です。しかも、テストデータで精度50%を越えなない場合は「正しい構築ができていない」ということなので、そこから修正が必要です。
各月初週の週間ランクに選ばれた楽曲といっても、10年ぶん以上の楽曲となるとかなりの量。この分析の記事制作のみならだいたい1週間程度で終わるくらいのボリュームなのですが、実際は学業などもろもろと並行しての作業だったので、データ収集に3週間程度、機械学習モデルの構築に3日ほど掛かりました……!
次に上記の楽曲のデータを取得します。今回はSpotifyのWEBAPIを利用して、得られる楽曲データを利用しました。楽曲ごとに取得する特徴量は下記の13種類です。
・アコースティック感
・踊れる曲になっているか
・曲の長さ
・曲のエネルギー量
・楽曲の長さに対する前・間・後奏の長さ
・キーの高低
・ライブっぽさ
・うるささ
・曲のスケール
・喋り口調で歌われているか
・平均BPM
・拍子
・曲のポジティブさ
これらの特徴量を取得するためにAPIの仕様に従って、楽曲のアーティストIDの取得→アルバムIDの取得→楽曲IDの取得を行い、楽曲idをもとに特徴量を取得します。Spotifyではアーティストやアルバム、各楽曲に固有のIDが割り振られていて、それによって各情報が識別されているためです。
アルバムID、楽曲IDも取得して、さらに特徴量を取得してひたすらカタカタ……。

カタカタ……。
ジャニーズの楽曲など、Spotifyで配信していない楽曲をのぞいて約10000曲の楽曲データを取得することができました。
これらのデータと、ヒットしなかった楽曲のデータを用いて、ヒットする場合としない場合の傾向をAIに学習させ、ヒット曲予測を行うAIを構築していきます。
これが2022年のヒット曲かも!? AIが算出した楽曲10選とは!?

テストデータに対して精度を測ってみた結果、86%となり大半のヒット曲を分類することができました!!
そして、構築したモデルに様々なメディアで2022年ブレイクアーティストとして選出された36組のアーティスト、合計293曲の楽曲情報を加えて、正例(ヒット)となる確率をもとに、楽曲/アーティストをランキングにしてみました!!
算出されたトップ10曲を発表します!!
トップ10の楽曲を実際に聴いてみると、誰かを想ったり、うまくいかない恋愛を歌った楽曲が多いように感じました。トレンドに囚われず、いつの時代にも恋愛ソングがヒットするというのは理解しやすい結果となりました。
技術的な話については、個人的に目標としていた精度90%には届きませんでした。これについては、今回用いたデータがBbillboardJAPAN HOT 100に選出された楽曲全てを対象として、様々な音楽ジャンル(邦ロック、洋楽から演歌、マルモのおきてまで多数)を取り扱っていたことが精度の伸び悩みの原因と考えられ、予測する楽曲ジャンルの対象を一つに絞ってモデルを構築すれば、モデルの精度は上がると思います。
ここで、注意していただきたいことが一つあります。
ここでのヒット確率というのは、降水確率が雨の強さや雨量と関係がないのと同じように、確率が高いからといって大ヒットを示しているわけではなく、単にヒットするかしないかの分類確率であることに注意してください。
自分でデータ取得、加工から分析結果を導くまで約3週間ほど時間を要し、
データの加工で手間暇をかければ質のいいデータを作成できるのですが、決められた製作時間のなかで、どこまで妥協するか、とても悩みました。
データが用意できれば、今回ヒット曲予測を行ったように機械学習を用いて、様々な分類や予測値を導き出すAIを開発することができます!
皆さんも是非チャレンジしてみてください!!
この記事を書いた人

清水 大良(しみず・たいら)
近畿大学 理工学部 情報学科4年生。近大広報室でインターン中。昼夜問わず深夜ラジオを聴く生粋のラジオリスナー。面白かった過去の放送回は何度も聴き返してしまう。近頃ラジオ局主催イベントが多く金欠気味。
編集:人間編集部
この記事をシェア
- リンクをコピーしました





